What Counts as a Data Product, and Why It Suddenly Matters
-

Ken Kasee is a 3x Telly Award-winning content marketer and digital marketing strategist with over 25 years of turning complex SaaS technology into clear, engaging stories.
The DataRadar™ Observability Framework covers five dimensions inside one native app:
Centralized data teams used to be the answer. In 2026, they are the bottleneck. As data demand grows and AI initiatives multiply, the old hub-and-spoke model is cracking under load. A new operating model is rising: domain-owned data products served through self-service platforms with built-in trust.
The Centralized Data Team Is Hitting a Wall
For most of the last decade, the standard model worked. One central data team built the pipelines. One team maintained the warehouse. One team answered every question that came in. The work was demanding, but the structure was straightforward.
That model is breaking under contemporary pressure. Enterprise AI initiatives are multiplying across business units. Self-service tools are everywhere. Business leaders want data faster than any single team can deliver it. The backlog grows. The team burns out. And the same problem keeps showing up across industries.
IBM research found that 82% of enterprises report data silos disrupt critical workflows, and as much as 68% of enterprise data goes unanalyzed.1 Centralization was supposed to fix silos. Instead, it just relocated them. Now the silo lives inside a single team’s queue.
Something has to change.
Why Data Mesh Principles Are Going Mainstream
Zhamak Dehghani introduced data mesh in 2019 as a way to scale data work without grinding the organization to a halt. Seven years later, the term is everywhere, and the conversation has matured. Thoughtworks describes the current state as hard-won maturity.2 The hype has cooled, and the principles have become foundational for data-driven enterprises.
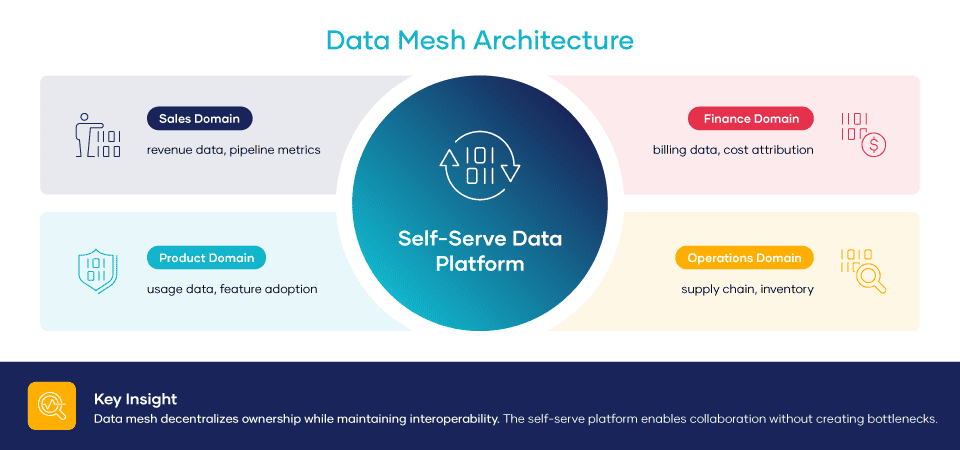
The four principles are simple to name and difficult to live with. Domain teams own their data. Data is treated as a product. A self-serve platform supports the domains. Federated computational governance keeps everything coherent across the enterprise.
The market is voting with budgets. The data mesh enablement services market is projected to grow by roughly $1.6 billion from 2026 to 2030, at a 17.6% compound annual growth rate.3 That is not a curiosity. That is enterprises spending real money on a different operating model.
But adoption looks different than the early hype suggested. Most successful organizations are not announcing a sweeping data mesh transformation. They are quietly adopting the parts that solve real problems and skipping the parts that do not. Industry observers note that incremental adoption beats big-bang transformations every time.4 The companies that announced sweeping programs and restructured everything at once often ended up with neither the benefits of decentralization nor the clarity of a centralized model.
What Makes Something a Data Product
Not every dataset qualifies as a data product. The word matters because it sets expectations.
A data product is an intentionally designed asset. It carries a contract. It has an owner. It comes with documentation and quality signals. Most teams agree on a short list of characteristics that separate a real data product from a raw table. A data product is discoverable, easy to find through a catalog or search. It is addressable and uniquely identifiable. It is understandable, with documentation that gives the data clear meaning. It is trustworthy, reliable and fresh, with visible quality metrics. It is self-describing, including metadata about itself. It is interoperable, easy to combine with other products. And it is secure, with controlled access.
When teams skip these characteristics, the value erodes. Practitioners note that the term data product has become so overused that its meaning varies from company to company.2 That is a warning. Without a shared definition, the discipline collapses back into a familiar pattern of calling a dataset a product without changing how it behaves. The format evolves, but the trust gap stays the same.
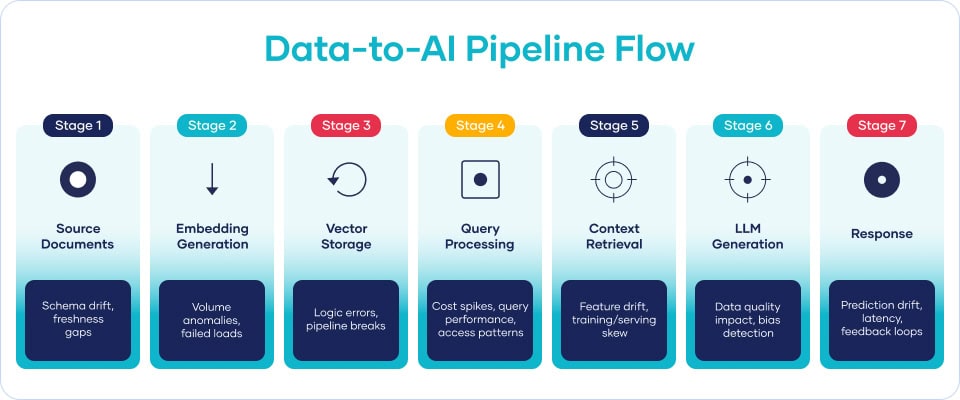
There is also a new flavor of data product worth watching. Some teams are publishing real-time inference endpoints from machine learning models as the output port of a data product. Others are serving event streams directly from the domain. The same discipline of ownership, contracts, and quality signals applies, but the surface area now extends beyond static tables. As agentic AI matures, this will only accelerate.
The Self-Service Layer Is Where Most Programs Break
Domain ownership only works if domains can serve themselves. Otherwise, the bottleneck just moves to platform engineering.
That is why self-serve platforms are the center of gravity for any serious productization effort. The platform handles the parts that should be common: storage, compute, access controls, monitoring, lineage, and quality scoring. The domains handle the parts that need context: the data itself, the business rules, the contracts that govern how the product is consumed.
Most failed efforts skipped the platform step. Teams declared domain ownership and then asked the same overworked central team to keep building everything. Predictably, nothing changed.
Successful programs build the platform first. Once teams can provision infrastructure without submitting tickets, domain ownership becomes possible. Then the program spreads. The platform team becomes a product team in its own right, with internal customers and a roadmap that responds to domain needs. Platform-as-a-product is often the most transferable lesson from data mesh, even for organizations that never adopt the full pattern.4
The cultural shift is the hardest part of the transition. IBM research found that 81% of chief data officers now practice bringing AI to the data rather than moving data to AI, and 82% are hiring for data roles that did not exist a year earlier.5 The roles, the skills, and the reporting lines all change. That is why most practitioners say data mesh is roughly 70% people and process, and 30% technology.
Observability Becomes the Connective Tissue
Distributed ownership creates a new kind of risk. Each domain may monitor its own products. Nobody sees the full picture.
When the marketing team’s data product changes, who tells the finance team that depends on it? When the customer 360 product is two days stale, how does anyone know? Without unified observability, decentralization turns into fragmentation. Domains move fast and break each other.
Unified observability solves the visibility problem without taking ownership away from domains. The platform provides the common layer for freshness, schema stability, lineage, and quality scoring. Each domain still owns its product. The platform makes it possible to trust the products as a coherent system.
Of the seven characteristics, trustworthy is the hardest to deliver and the easiest to fake. Anyone can put a quality badge on a dataset. Real trust requires monitoring that catches problems before consumers do. That is the observability layer doing its job, quietly, before anyone has to ask.
The Trade-Offs Are Real
Data productization is not a free upgrade. The trade-offs are well documented and worth naming honestly.
Governance is harder when data is distributed. Security policies need to be enforced across domains, not in one central place. Skills become uneven across the organization. Some domains will run their data products well and some will not. Coordination across domains takes effort that centralized teams used to absorb invisibly. New regulations, including the EU Data Act, are pushing the same discipline into how enterprises share data with each other, which raises the stakes further.2
The honest answer is that decentralization works best for organizations that already operate through independent business units. Large enterprises with distinct product lines and mature data practices see the most success. Smaller organizations or those with a single product line often do not need the full pattern.
The principles still apply. Treating data as a product, building a self-serve layer, and measuring trust are valuable even without a full mesh implementation. The lesson generalizes: ownership belongs as close to the domain as possible, and the platform should make doing the right thing easier than doing the wrong thing.
The AI-Ready Connection
There is one more reason this trend is moving so quickly. Data products and AI readiness are converging. AI agents and machine learning models depend on trusted, well-governed data with clear lineage. Raw tables do not meet that bar. Data products do. The teams that have already invested in productization are finding that they have a head start on the AI-ready data foundation that every enterprise now needs. Self-service for analysts becomes self-service for agents. The discipline is the same.
Where to Start
For teams new to this, the path is well marked.
Pick two domains with clear boundaries and real business problems. Build the self-serve platform capabilities those domains need. Define what data product means inside the organization, including the trust signals that consumers can rely on. Connect observability to the domain layer from the beginning, not as an afterthought. Expand slowly across quarters, not weeks.
The organizations that succeed in 2026 will not be the ones that bought the most tools. They will be the ones that did the hard organizational work, treated data as a product, and made trust measurable across distributed teams.
Key Takeaways
-
Centralization does not fix data silos. It just moves them into a single team’s queue.
-
Data mesh is mainstream now, but only when adopted incrementally. Big-bang transformations fail.
-
A data product is not a dataset. It has an owner, a contract, documentation, and visible trust signals.
-
Self-serve platforms are the part most programs skip, and the part most programs regret skipping.
-
The cultural shift is roughly 70% people and process, 30% technology. Plan accordingly.
-
Unified observability is what turns a mesh of products into a coherent system you can trust.
-
Data products are the on-ramp to AI-ready data. Self-service for analysts becomes self-service for agents.

Sources
¹International Business Machines Corporation. (2026, March 5). What are data silos? IBM Think. https://www.ibm.com/think/topics/data-silos
²Thoughtworks. (2026, January 16). The state of data mesh in 2026: From hype to hard-won maturity. https://www.thoughtworks.com/insights/blog/data-strategy/the-state-of-data-mesh-in-2026-from-hype-to-hard-won-maturity
3Technavio. (2026, March). Data mesh enablement services market growth analysis: Size and forecast 2026-2030. https://www.technavio.com/report/data-mesh-enablement-services-market-industry-analysis
4Starburst Data, Inc. (2025). Data mesh: What happened? https://www.starburst.io/blog/data-mesh-what-happened/
5AI News. (2025, November 13). IBM: Data silos are holding back enterprise AI. https://www.artificialintelligence-news.com/news/ibm-data-silos-are-holding-back-enterprise-ai/