RAG Observability: The Four Gaps in Your AI Pipeline
-

Ken Kasee is a 3x Telly Award-winning content marketer and digital marketing strategist with over 25 years of turning complex SaaS technology into clear, engaging stories.
Your customer service chatbot just gave the wrong answer to a frustrated customer. Your sales team’s AI assistant just pitched a product you stopped selling six months ago. Your in-house knowledge base is pulling answers from an outdated policy that compliance replaced last quarter.
In each case, the AI model is working fine. The problem is the data feeding it.
Welcome to the new data quality challenge that traditional observability tools cannot solve: Retrieval-Augmented Generation, or RAG.
RAG is now the standard pattern for enterprise AI. The market reached $1.85 billion in 20251. Almost every serious AI rollout uses RAG to ground LLM responses in proprietary data. But as these rollouts scale from pilot to production, organizations are hitting a hard truth. Their existing data tools cannot see RAG at all. The cost of that blind spot shows up in customer trust, audit risk, and lost revenue.
How Does RAG Work?
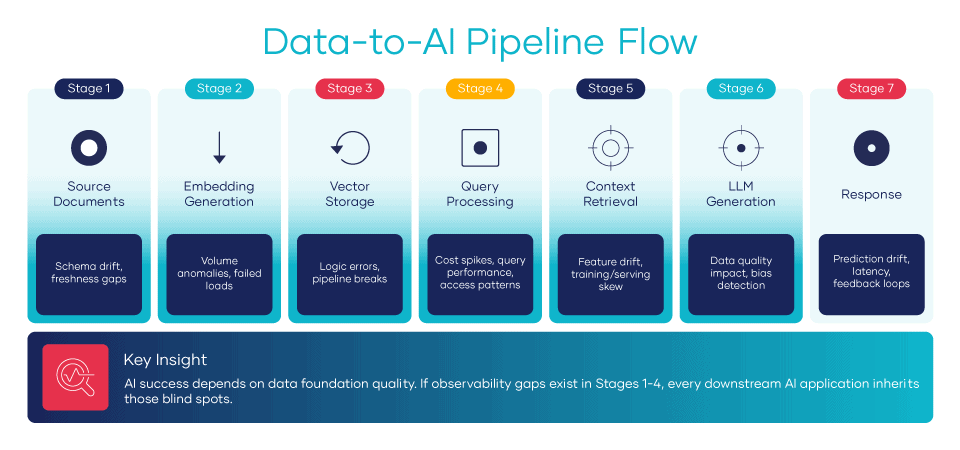
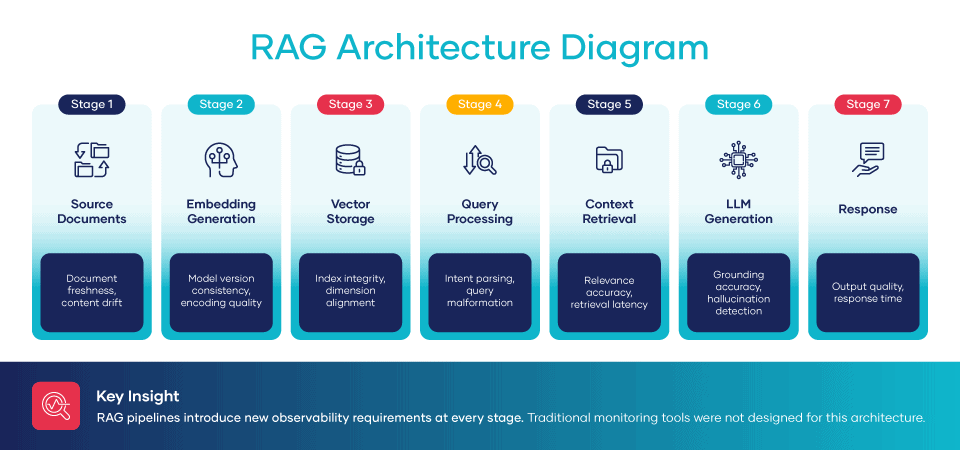
Before we can identify the gaps, we need to see what we are looking at. RAG runs as a seven-stage pipeline. Each step is a place where quality can quietly break down.
- Ingest. Source documents such as policies, product information, support articles, tickets, and contracts are pulled from systems across the enterprise.
- Transform. Files are chunked, cleaned, and tagged with metadata for processing.
- Embed. An embedding model turns each chunk into a vector. A vector is a string of numbers that represents meaning.
- Store.Vectors get loaded into a vector database built for fast similarity search across millions of records.
- Retrieve. When a user submits a question, the system pulls the chunks that match it most closely.
- Generate. An LLM produces a response based on those chunks, ideally with citations back to the source.
Each step adds risk. Traditional data tools, designed for pipelines that end at a dashboard, miss every one of them.
The Four RAG Observability Gaps
RAG creates new quality risks that most organizations cannot monitor with their current tools. Here are the four critical gaps every data leader has to close.
Gap 1: Vector Freshness
The question: Are your vectors current or built from outdated source data?
When a source file changes, the vectors derived from it must be regenerated. But most organizations do not track this dependency. The product page was updated yesterday, but the embedding still reflects last month’s pricing. The compliance policy was revised after a regulatory change, but no one refreshed the vector store. The AI cites the outdated information with full confidence. No one notices until a customer, an auditor, or a reporter does.
Gap 2: Retrieval Relevance
The question: Are your vectors current or built from outdated source data?When a source file changes, the vectors derived from it must be regenerated. But most organizations do not track this dependency.
The product page was updated yesterday, but the embedding still reflects last month’s pricing. The compliance policy was revised after a regulatory change, but no one refreshed the vector store. The AI cites the outdated information with full confidence. No one notices until a customer, an auditor, or a reporter does.
Gap 3: Context Completeness
The question: Is there enough context to answer, or is the LLM filling gaps with hallucinations?
LLMs are designed to produce fluent, confident responses. When the context is thin, they do not pause and admit uncertainty. They generate plausible text by drawing on their training data instead. That guess might be inaccurate, outdated, or off-topic for your business. Without observability into context coverage, you cannot tell a grounded response from a confident hallucination. They look identical to the user.
Gap 4: Semantic Accuracy
The question: Do generated responses match what the source files actually say?
Even with the right context, the LLM can twist the source. It might combine two documents in ways that change the meaning. It might soften a strict policy or oversell a marketing claim. To catch this, organizations have to validate each response against the source. At scale. Continuously. Across every query type the business serves. Traditional observability tools cannot do this at all.
Scroll for more
| Component | The Challenge | What Goes Wrong |
|---|---|---|
| Vector Freshness | Are vectors current with source data? | AI cites outdated information |
| Retrieval Relevance | Are the results contextually appropriate? | Wrong documents inform responses |
| Context Completeness | Is there enough info to answer? | LLM fills gaps with hallucinations |
| Semantic Accuracy | Does the response reflect sources? | Answers misrepresent the source material |
Why Traditional Tools Cannot Monitor RAG
Traditional data observability was designed for a simpler world. Data flows from the source through transformation to the dashboard. You monitor row counts, freshness, schema changes, and statistical anomalies. When something breaks, you trace it back through the pipeline using lineage.
RAG breaks that model in four core ways.
-
Unstructured data.Traditional tools monitor tables and columns. RAG processes documents, PDFs, images, and text chunks. None of those fit a schema. None have a row count to validate against.
-
Semantic transforms. Turning text into vectors is not a deterministic step. The same input can yield different outputs depending on the embedding model, its version, or even minor text tweaks before the run. There is no checksum to verify integrity.
-
Non-linear flows. RAG pipelines do not flow in one direction. Queries go in, context comes out, responses are built, and the whole loop runs again on follow-ups. Lineage becomes a graph rather than a tree.
-
Probabilistic outputs.LLM responses are not deterministic. The same prompt can yield different outputs across runs. Correctness becomes a spectrum, not a binary, and traditional pass-fail data quality checks have no language for it.
This is why organizations deploying RAG often end up flying blind. They have great visibility into their data pipelines and zero visibility into the AI systems sitting on top. The dashboard says green. The customers say otherwise.
What RAG Observability Requires
Organizations need one unified view that spans the whole data-to-AI pipeline. When model accuracy drops, you have to trace it back. Is it a model issue? A feature issue? A source data issue? When source data quality dips, you have to project forward. Which models and apps will feel it, and how soon?
That requires capabilities most data observability platforms do not ship today.
-
Vector freshness monitoring.Track when each embedding was built and how that aligns with source file updates. Set automated alerts when the drift gets too wide.
-
Retrieval quality metrics.Measure relevance scores, result diversity, search speed, and the rate of zero-result queries that point to gaps in your data.
-
Response grounding checks.Compare generated responses against source files for accuracy, attribution, and coverage. At scale, continuously.
-
End-to-end lineage. Trace any response from the final output back to the source files that fed it. Fix issues in minutes, not days.
Organizations that build this unified view can deploy AI at scale with confidence. They can defend it to auditors, the board, and customers. Organizations that do not will keep poking at black boxes one ticket at a time.
How RAG Observability Connects to Other Trends
RAG observability does not stand alone. It intersects with other trends shaping data observability this year.
Predictive Observability. ML-powered anomaly detection can identify when vector freshness or retrieval quality begins slipping before users feel the impact. That shifts the response from reactive firefighting to proactive prevention.
Cost-Aware FinOps. RAG has direct cost implications. Pulling too many chunks or oversizing the context window increases token costs on every query. Poor source data quality pushes teams to broaden the context to compensate, further increasing costs. Observability is what makes real cost optimization possible.
Agentic AI Governance. When AI agents take autonomous actions on RAG output, the stakes climb sharply. You need audit trails from each action back to the source files that justified it. That matters in any business, but it is the law in regulated ones.
Key Takeaways: RAG Observability
- RAG is the dominant pattern for enterprise AI. A $1.85B market growing 49% per year. If you are deploying AI, you are deploying RAG.
- Traditional is blind to RAG. Tools built for tabular pipelines cannot see unstructured data, semantic transforms, or probabilistic output.
- Four critical gaps emerge. Vector freshness, retrieval relevance, context coverage, and semantic accuracy. Each one can break your AI. Most organizations are not monitoring any of them today.
- Unified visibility is the goal. Trace every response from the source file to the final reply. Anything less is debugging a black box.
- It connects to cost, governance, and prediction. RAG observability is not a side topic. It intersects with every major 2026 trend on the data leader’s agenda.

Sources
1Precedence Research. (2025, December 1). Retrieval augmented generation market size, share, and trends 2025 to 2034. Precedence Research. . https://www.precedenceresearch.com/retrieval-augmented-generation-market