The Data Observability Market Has Bifurcated: Quality vs. Cost
-

Ken Kasee is a 3x Telly Award-winning content marketer and digital marketing strategist with over 25 years of turning complex SaaS technology into clear, engaging stories.
Here’s a question that shouldn’t be hard: If a data quality issue is causing you to reprocess a pipeline three times a day, how much is that issue costing you?
In theory, this is a simple calculation. You know the compute cost per run. You know the frequency. Multiply, and you have your answer.
In practice, almost no organization can answer this question because the tools that monitor data quality and cloud costs exist in entirely separate universes.
This is the bifurcation problem. And it’s costing enterprises more than they realize.
The 340% Explosion
Cloud data spending has increased by 340% from 2022 to 2025.¹ What was once a manageable line item has become a board-level concern. CFOs are asking tough questions about cloud ROI, and data teams are scrambling to justify spending.
At the same time, data quality issues are causing $12.9 million in annual losses per organization.² These two problems—runaway costs and persistent quality issues—are deeply connected. But the market treats them as if they’re entirely separate disciplines.
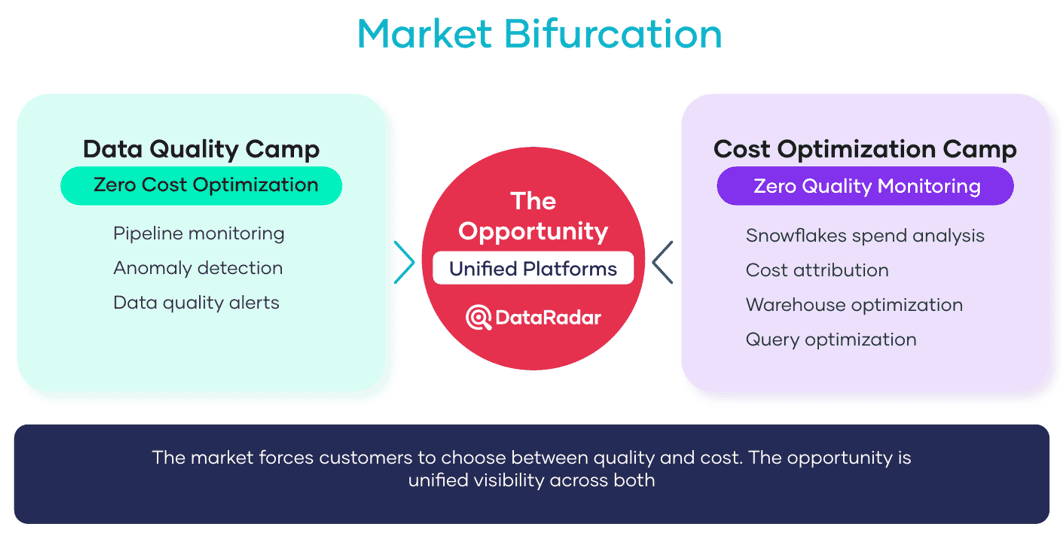
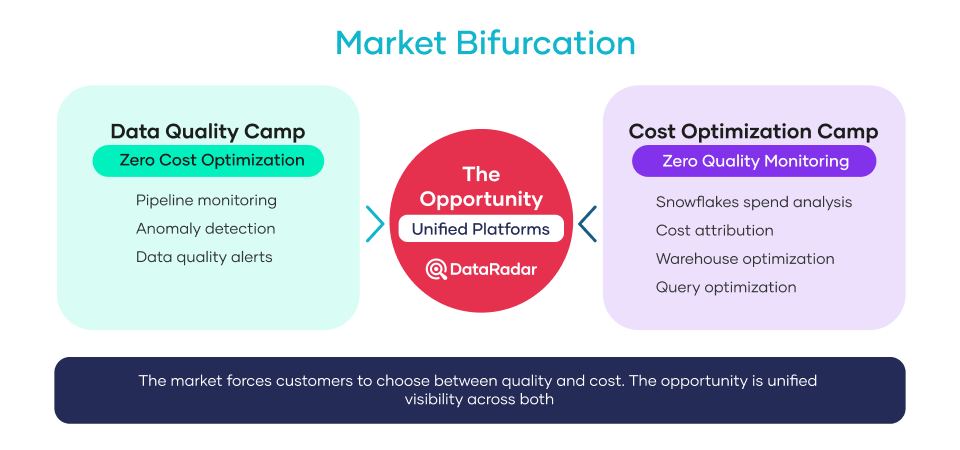
Two Camps, Zero Overlap
Walk through the data tooling landscape, and you’ll discover two main groups that never intersect: one focused on data quality, the other on cost optimization. The data quality group is dedicated to monitoring, enforcing rules, and automating checks within data pipelines to ensure accurate and reliable data for analytics and decision-making. Meanwhile, the cost optimization group approaches data pipelines from the perspective of managing resources, reducing waste, and identifying inefficiencies like zombie pipelines. Both groups work with data pipelines, but their priorities—quality monitoring versus cost reduction—shape their tools and strategies.
The Data Quality Camp
Many companies have built sophisticated observability platforms. These platforms monitor freshness, schema changes, anomalies, and lineage. They implement data quality checks and data validation rules to ensure data integrity and accuracy across systems. Comprehensive data quality assessment is also a core function, enabling organizations to evaluate and improve their data quality using frameworks that address accuracy, completeness, and timeliness. They’re excellent at telling you what’s wrong with your data.
But ask them how much a particular quality issue is costing you in compute. They have no idea. Ask them which tables are consuming most warehouse credits. Not their department. Ask them to identify zombie pipelines that are burning the budget. Crickets.
The Cost Optimization Camp
There are about half a dozen companies with tools that have built ML-powered cost-optimization features. They can identify inefficient queries, suggest warehouse rightsizing, and forecast spending. They’re great at showing what’s expensive. These tools often analyze data from multiple sources but lack insight into the quality of data from those sources.
But ask them whether that expensive query is processing good data or garbage? No visibility. Ask them if the cost spike correlates with a quality incident? Can’t tell you. Ask them which quality issues are driving reprocessing costs? Not in their wheelhouse.
The Central Insight: They’re the Same Problem
Here’s what the bifurcated market misses: cost optimization and data quality are deeply connected. You cannot optimize one without understanding the other.
Poor data quality drives up costs through:
- Reprocessing failed pipelines: Every retry burns compute credits
- Manual correction efforts: Human time is expensive
- Wasted compute on bad data, poor quality data, and low quality data: Processing garbage yields nothing
- Zombie pipelines: Processes nobody needs still consume budget
Data quality issues can stem from incompleteness, inaccuracy, inconsistency, or data duplication. Such issues can lead to regulatory penalties, financial losses, and reputational damage for organizations.
Meanwhile, cost optimization without quality context is dangerous:
- Cut costs on a critical pipeline? You might create data freshness issues that cost far more downstream
- Rightsize a warehouse aggressively? You might introduce latency that breaks SLAs
- Optimize a query that’s already processing insufficient data? You’re making garbage faster
It is essential to provide reliable data to data consumers so they can make accurate and informed decisions.
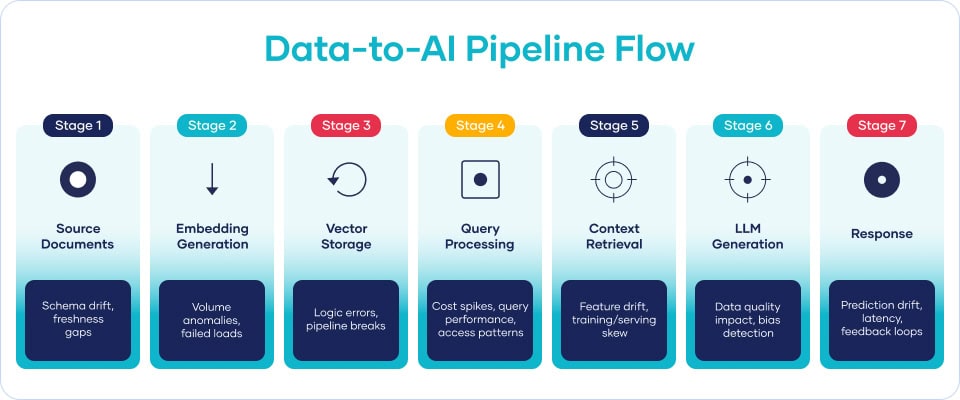
Understanding How Poor Data Quality Is Actually Costing You
To balance quality and cost, you need to understand where cloud data actually goes. In Snowflake environments (the dominant enterprise data platform), costs break down into distinct categories:
Table 5.1 The Cost Drive and Quality Connection
Scroll for more
| Cost Driver | Pricing | Quality Connection |
|---|---|---|
| Compute Warehouses | $2-4 per credit | Quality issues → reprocessing → credit burn |
| Cortex AI Inference | Per million tokens | Poor data → larger prompts → higher token costs |
| Cortex Search | Per the indexed document | Stale/duplicate docs → wasted indexing spend |
| Storage | Per TB/month | No cleanup of insufficient data → storage bloat |
| Egress | $0.09/GB | External tools extracting data → egress fees |
Each of these cost drivers has a quality dimension. Organizations winning at FinOps track both cost and quality as unified metrics, achieving 20-40% cost reduction while maintaining or improving data quality.
Data quality refers to the overall state of a dataset and its appropriateness for decision-making and compliance. It measures how well a dataset meets criteria such as accuracy, completeness, validity, consistency, uniqueness, timeliness, and fitness for purpose. Data quality is assessed based on several key dimensions, including accuracy, completeness, and consistency—these are known as the dimensions of data quality or data quality dimensions. Organizations employ data quality assessment frameworks to categorize metrics and systematically evaluate and enhance data quality across these dimensions.
The Impact of Inaccurate Data
Data quality isn’t something most businesses think about every day, until they really need it. Whether you’re running daily reports, making strategic decisions, or trying to serve your customers better, having accurate data can make all the difference when business challenges come your way.
You know that feeling when your data just doesn’t add up? When customer records don’t match, reports contradict each other, or you’re making decisions based on information you’re not sure you can trust? That’s poor data quality at work, and it’s more than just a minor headache—it can hurt your business strategies, damage customer relationships, and cost you real money. For businesses like yours in insurance, finance, and healthcare, the stakes get even higher. One data mix-up can mean compliance headaches, missed opportunities, or having to redo work you thought was already done.
Here’s the thing: high-quality data is the foundation of everything else. When your data is accurate, complete, and reliable, you can make decisions confidently, run your operations smoothly, and deliver the experience your customers deserve. Managing data quality isn’t just about fixing what’s broken—it’s about fostering a workplace where everyone cares about keeping data clean and useful.
Data problems often start small—such as inconsistent data formats, missing values, duplicate records, or errors during data entry or transfer. But these issues can quickly escalate as your data expands and moves through different systems. Without proper controls, you risk making decisions based on incomplete or incorrect information, which can lead to poor results and wasted time and money.
The good news is that solid solutions exist to address these challenges. Modern data quality tools can detect issues and notify you immediately, while data profiling and cleansing software help you identify and correct inconsistencies. Master data management systems ensure your most important information—like customer profiles and policy details—remains accurate and current across all platforms. Establishing a strong data governance framework with clear data quality rules and validation checks is essential for maintaining data reliability and meeting your organization’s standards.
Checking your data quality should be thorough and ongoing. You should regularly assess data quality in key areas: accuracy, completeness, consistency, validity, timeliness, and whether it meets your needs. By monitoring various data issues and tracking improvements over time, you and your team can focus efforts where they will have the greatest impact.
Today’s data quality solutions are becoming smarter, thanks to artificial intelligence and machine learning. These enhanced solutions can automatically identify patterns, predict issues before they arise, and recommend fixes—helping you stay ahead of data quality challenges even as your data grows and becomes more complex.
Ultimately, effective data quality management isn’t a one-time project—it’s something you commit to over the long haul. When you invest in data quality best practices like continuous monitoring, regular quality checks, and training your team, you’re setting yourself up to work more efficiently, improve operational effectiveness, stay compliant with regulations, and build genuine trust with your customers.
By using advanced data quality tools, implementing strong data governance practices, and promoting a data quality culture where everyone values good data, you can turn your organization’s data into a genuine business advantage that fuels growth, reduces risk, and provides value to your customers and stakeholders.
The Token Economy Challenge
Here’s where the quality-cost link becomes even more important: the rise of AI is adding a completely new cost factor.
Large language models charge based on the number of tokens. Every word in a prompt, every piece of retrieved context, and every generated response all incur costs. Data quality directly affects AI expenses in three ways most organizations haven’t yet understood.
- Poorly structured data requires more tokens to process. Clean, well-organized data with high accuracy and consistency is more token-efficient, boosting AI efficiency.
- Missing context forces larger retrieval windows. Incomplete data means retrieving more to compensate.
- Inconsistent data formats break caching strategies. Every variation requires reprocessing.
High data quality allows for confident, informed decisions and is crucial for effective decision-making, especially for data scientists and in the insurance industry. Organizations must continuously improve data quality to optimize AI costs and results.
The Case for Unified Data Quality Management Platforms
The opportunity is clear: organizations that unify data quality and cost optimization in a single platform gain capabilities that neither can provide alone. Unified platforms allow organizations to maintain data quality through robust quality control and ongoing efforts, ensuring accurate, reliable, and standardized data. Maintaining data quality is crucial for trust and efficiency, supporting better decision-making and operational effectiveness. Fostering a data quality culture and striving for good data quality are essential for successful improvement, as they promote employee education, continuous training, and organizational buy-in. Data quality management involves ongoing processes to identify and fix errors, inconsistencies, and inaccuracies, which helps prevent issues and ensures compliance.
- Root cause visibility: See which quality issues are driving cost spikes
- Prioritized remediation: Fix the quality issues with the highest cost impact first
- Safe optimization: Reduce costs without creating quality problems
- Zombie detection: Identify pipelines consuming budget without delivering business value
- Simplified tooling: One platform, one security review, one vendor relationship
This isn’t about adding another tool to the stack. It’s about understanding that quality and cost are two angles on the same core reality and managing them appropriately.
Key Takeaways
- The market has bifurcated unhelpfully. Quality tools and cost tools have no overlap, resulting in fragmented solutions for connected problems.
- Cloud spend is up 340%. CFOs are asking tough questions. Data teams need to connect quality investments to cost outcomes.
- Quality and cost are inseparable. Poor quality drives up costs. Blind cost-cutting creates quality issues. You can’t optimize one without optimizing the other.
- AI makes this more urgent. Token-based pricing means data quality directly impacts AI costs in ways most organizations can’t yet track.
- Unified platforms are the answer. The organizations winning in 2026 aren’t managing quality and cost separately; they’re working with them together.

Sources:
¹ Ashare, M. (2024, November 19). Global cloud spend to surpass $700B in 2025 as hybrid adoption spreads. CIO Dive. https://www.ciodive.com/news/cloud-spend-growth-forecast-2025-gartner/733401/
² (2024). The cost of poor data quality. Gartner Research. https://www.gartner.com/en/data-analytics/topics/data-quality