
The Freshness-Accuracy Paradox: Real-Time Data Quality at Scale
-

Ken Kasee is a 3x Telly Award-winning content marketer and digital marketing strategist with over 25 years of turning complex SaaS technology into clear, engaging stories.
Five years ago, “real-time” was a stretch goal for most enterprises. Data refreshed daily, and that was considered fast. Reports ran overnight. Dashboards updated in the morning, and analysts spent the first hour of each day catching up to the previous day’s activity.
Today, real-time is the baseline expectation. Customers expect instant personalization. Operations demand up-to-the-minute visibility. AI models need fresh data to make relevant predictions. The shift has been swift, and the pressure to keep pace is intense.
The numbers tell the story. In its 2025 Data Streaming Report, Confluent surveyed 4,175 IT leaders across 12 countries. The report found that 86% rank data streaming as a top strategic or important priority, and 90% plan to increase their data streaming spend 1. Eighty-nine percent see streaming platforms as critical to reaching their data goals 2.
But here is what most organizations missed in the rush to real-time: they accelerated their data pipelines without accelerating their quality controls.
The result? They are now making decisions faster than ever; on data they have not validated.
The Freshness-Accuracy Paradox
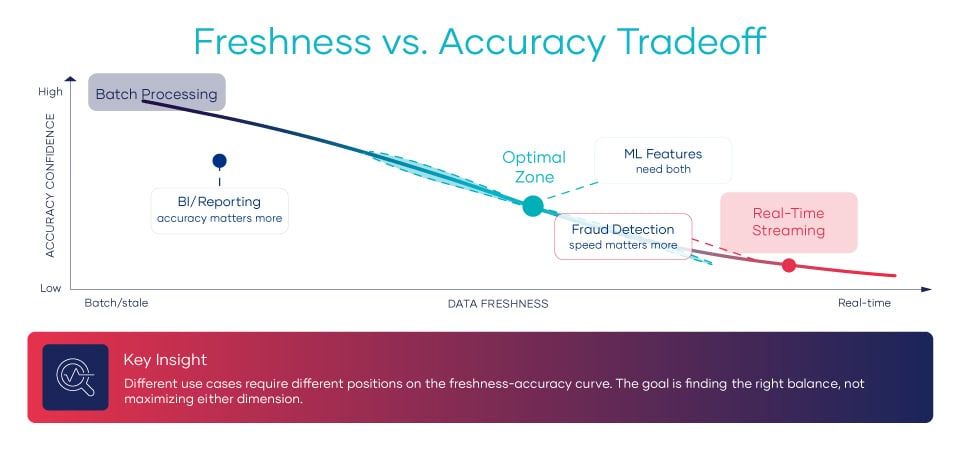
Real-time data creates a paradox that batch processing never faced: the faster data moves, the less time there is to validate it.
In batch processing, you had built-in validation windows. Data arrived, sat in staging, got checked, and then moved to production. Hours might pass between ingestion and consumption. There was plenty of time for quality gates and human review. If something looked off, you could pause the load and investigate.
In streaming architectures, data moves continuously. Events flow through pipelines in milliseconds. There is no natural pause point for quality checks. The very speed that creates business value also strips away the buffer that traditional quality programs depended on.
This creates the freshness-accuracy tradeoff that every data leader now faces:
- Prioritize freshness: Data arrives fast but may contain errors that propagate before detection.
- Prioritize accuracy: Extensive validation occurs, but data is stale by the time it is available.
- The balanced answer: Shift-left validation that embeds quality checks in the stream itself.
Monte Carlo, the data observability vendor, has documented this challenge directly. The company notes that stream processing must handle errors while maintaining continuous operation, and a problem in stream processing logic affects all subsequent events until you deploy a fix 6. That is a sharp contrast with batch, where teams have time to investigate causes and fix issues before the next processing cycle.
What “Shift-Left” Actually Means
In software development, shift-left means moving testing earlier in the development cycle. The idea is simple: catch bugs during coding, not after deployment. The same principle now applies to data.
For data, shift-left means moving quality validation earlier in the data lifecycle. Catch issues at ingestion, not after they have propagated through your entire pipeline.
This is not just a slogan. The 2025 Data Streaming Report found that 81% of IT leaders reduced costs and risks across development and operations by adopting a shift-left approach to data processing and governance. Ninety-three percent cite at least four benefits of embracing the strategy 3. Those benefits include better data quality, lower processing costs, less effort for downstream consumers, and reduced overall risk.
Shift-left validation includes four core capabilities:
-
Schema validation at ingestion.Before a record enters your pipeline, validate that it conforms to the expected structure. Reject malformed data right away, before it causes downstream issues.
-
Real-time business rule checks. As data flows through transformations, validate against domain constraints. A negative price, a future birth date, a customer ID that does not exist: catch these in flight.
-
Automated quarantine. When data fails validation, do not let it block the entire stream. Route bad records to a quarantine zone for review while the valid data continues flowing.
-
Immediate alerting. Notify teams of issues in real-time, while the context is fresh. Debugging an issue that happened 30 seconds ago is far easier than debugging one from last night’s batch.
Confluent describes this pattern as building validation and monitoring directly into your real-time pipelines, where systems act as gatekeepers at the source. The goal is to ensure that only clean, accurate, and trusted data enters business-critical workflows 4.
The Architecture Challenge
Implementing shift-left validation in streaming architectures is not trivial. Traditional quality tools were built for batch, and the assumptions baked into those tools do not hold up in motion.
Scroll for more
| Batch Paradigm | Streaming Paradigm |
|---|---|
| Data at rest | Data in motion |
| Query after landing | Process during transit |
| Minutes or hours for checks | Milliseconds for checks |
| Reprocess if wrong | Cannot un-ring the bell |
| Full dataset available | One record at a time |
The tools and techniques that work for batch do not translate directly. You cannot run a 30-second query against a single event that needs to be processed in 30 milliseconds. The math just does not work.
This is why real-time quality requires purpose-built capabilities:
- Stateless validation. Checks that can execute on individual records without requiring a full dataset context.
- Statistical windows. Anomaly detection based on rolling aggregates rather than full scans.
- Probabilistic approaches. Approximate answers fast, rather than exact answers slow.
- Async validation. Some checks run in parallel, flagging issues after the fact while allowing the stream to continue.
The good news is that the tooling has caught up to the problem. Native, in-platform validation now lets teams enforce schemas, run business rules, and route quarantined records without bolting on outside tools or copying data to a separate environment.
The Consequences of Delay
Why does this matter so much? Because in real-time systems, delayed quality detection means amplified impact.
Consider a streaming pipeline feeding a fraud detection model. If bad data enters the stream:
- At T+0: One record is wrong.
- At T+1 minute: The model has processed 1,000 records influenced by the bad data.
- At T+10 minutes: 10,000 potentially wrong fraud decisions have been made.
- At T+1 hour: The downstream impact is massive and possibly unrecoverable.
In batch systems, you might catch the issue in the next nightly run. In streaming systems, waiting until tomorrow means thousands of additional bad decisions. Each one shapes a customer experience or triggers an action that is hard to take back.
The financial stakes are real. The IBM Institute for Business Value reports that more than a quarter of organizations estimate they lose at least $5 million annually due to poor data quality, while 7% report losses of $25 million or more 5. The same study found that 43% of chief operations officers identify data quality as their top data priority, and 45% of business leaders cite data accuracy or bias as a leading barrier to scaling AI initiatives 5.
Real-time data without real-time quality is a risk amplifier, not an improvement.
The Alert Fatigue Trap
There is one more wrinkle worth flagging. Building real-time quality monitoring is not enough on its own. You also have to design the alert experience for human attention spans.
Monte Carlo’s analysis of more than 11 million monitored tables shows that the engagement rate on alerts drops by about 15% once a notification channel receives more than 50 alerts per week. Engagement drops another 20% once that channel crosses 100 alerts per week 7. In other words, more alerts do not equal better quality. Past a certain threshold, more alerts equal less response.
The lesson: real-time quality programs need smart triage built in. Group related alerts. Suppress duplicates. Route by severity and business impact. The goal is not to detect every anomaly. The goal is to ensure the right person sees the right issue at the right time.
What Good Looks Like
What does mature real-time quality look like in practice? It looks like this:
- Schema enforcement at every ingestion point, not just at the warehouse boundary.
- Business rules expressed as code, version-controlled, and tested like application logic.
- Quarantine and replay capabilities so bad data can be fixed and reprocessed without halting the pipeline.
- Lineage that reaches across batch and streaming systems, so teams can trace any anomaly back to its source.
- Alert routing that respects on-call hours, severity, and business ownership.
Most organizations are not there yet. The 2025 Data Streaming Report shows the streaming market is still maturing. Twenty-five percent of IT leaders identify as Level 1 in streaming maturity, up from just 8% in 2024 1. That growth is encouraging. It also reveals how many teams are still early in their journey. The risk is that they will scale streaming throughput before scaling streaming quality and inherit a much larger problem to solve later.
The takeaway for data leaders is clear. If you are investing in streaming, invest in streaming quality at the same time. Treat the two as one program, not two. The teams that get this right will move fast and trust their data. The teams that get it wrong will move fast and regret it.
Key Takeaways
-
Real-time data is the baseline expectation.Customers, operations, and AI models all demand fresh data. Eighty-six percent of IT leaders treat streaming as a strategic priority1.
-
Most organizations accelerated data without accelerating quality.They are making faster decisions on unvalidated data. That is not an improvement.
-
The freshness-accuracy paradox is real.Faster data means less time for validation. Shift-left approaches are the most practical answer, and 81% of IT leaders who adopted them reported lower costs and risks 3.
-
Shift-left means validating at ingestion.In streaming systems, every minute of delay means thousands more records affected. The cost of poor data quality routinely runs into the millions 5.
-
<strong class="u-text-blue"Alerting design matters. Past 50 alerts per week, response rates fall sharply 7. Build triage into your real-time quality program from day one.
Ready to See What Real-Time Quality Looks Like?
Start with the playbook.
Request a demo, solo or with your team.
Take the 30-day trial.
References
1.Add New Post ‹ Dataradar Blog — WordPressConfluent. (2025a). Data streaming enables AI product innovation, say 90% of IT leaders in Confluent’s new Data Streaming Report [Press release]. https://www.confluent.io/press-release/data-streaming-report-2025/
2.Confluent. (2025b). The 2025 Data Streaming Report: Real-time data, real business results. https://www.confluent.io/resources/report/2025-data-streaming-report/
3.Confluent. (2025c). Just launched: 2025 Data Streaming Report [Blog post]. https://www.confluent.io/blog/2025-data-streaming-report/
4.Confluent. (2025d). Ensure data quality with real-time validation and monitoring [Blog post]. https://www.confluent.io/blog/making-data-quality-scalable-with-real-time-streaming-architectures/
5.IBM. (2026). A compounding threat: The true cost of poor data quality. IBM Think Insights. https://www.ibm.com/think/insights/cost-of-poor-data-quality
6.Monte Carlo. (2025a). Batch processing vs stream processing: The data quality dimension [Blog post]. https://www.montecarlodata.com/blog-batch-processing-vs-stream-processing/
7.Monte Carlo. (2025b). Data quality statistics and insights from monitoring 11 million tables in 2025 [Blog post]. https://www.montecarlodata.com/blog-data-quality-statistics/

